How It Works
Look Inside YottaDB
Take a deep dive into YottaDB's data structures, persistent data journaling, transaction processing, and business continuity.
Data Structure: Key-Value Tuples
The fundamental core data structure provided by YottaDB is key-value tuples. For example, the following is a set of key value tuples:
["Capital","Belgium","Brussels"] ["Capital","Thailand","Bangkok"] ["Capital","USA","Washington, DC"]
Each of the above tuples is called a node. In an n-tuple, the first n-1 items are keys, and the last item is the value associated with the keys. Data in YottaDB is always ordered according to the keys – there is never a need to explicitly sort data.
Even though YottaDB itself assigns no meaning to the data in each node, application maintainability is improved by using meaningful keys, for example:
["Capital","Belgium","Brussels"] ["Capital","Thailand","Bangkok"] ["Capital","USA","Washington, DC"] ["Population","Belgium",1367000] ["Population","Thailand",8414000] ["Population","USA",325737000]
As YottaDB assigns no inherent meaning to the keys or values, its key value structure lends itself to implementing Variety. For example, if an application wishes to add historical census results under “Population”, the following is a perfectly valid set of tuples:
["Capital","Belgium","Brussels"] ["Capital","Thailand","Bangkok"] ["Capital","USA","Washington, DC"] ["Population","Belgium",1367000] ["Population","Thailand",8414000] ["Population","USA",325737000] ["Population","USA",17900802,3929326] ["Population","USA",18000804,5308483] … ["Population","USA",20100401,308745538]
In the above, the application designer has chosen to represent dates in the form yyyymmdd, e.g., 17900802 represents August 2, 1790. An application would determine from the number of keys whether a node represents the current population or historical census data.
The first key is called a variable, and the remaining keys are called subscripts allowing for a representation both compact and familiar to a programmer, e.g., Capital(“Belgium”)=”Brussels”. The set of all nodes under a variable is called a tree (so in the example, there are two trees, one under Capital and the other under Population). The set of all nodes under a variable and a leading set of its subscripts is called a subtree (e.g., Population(“USA”) is a subtree of the Population tree).
With this representation, the Population tree can be written as follows:
Population("Belgium")=1367000
Population("Thailand")=8414000
Population("USA")=325737000
Population("USA",17900802)=3929326
Population("USA",18000804)=5308483
…
Population("USA",20100401)=308745538
And visualized thus:
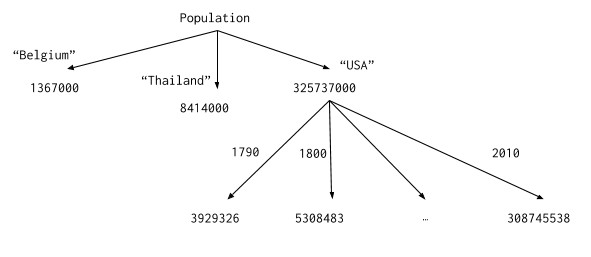
It is important to note that in YottaDB, some subtrees can be deeper than other subtrees, and even nodes that have values can have subtrees (i.e., descendants). It is important to contrast this with the popular JSON format – while every JSON structure can be represented by a YottaDB tree or subtree, the reverse is not true because JSON does not permit a node to both have a value as well as descendants. Since YottaDB makes no restrictions on application schema, applications that intend to export their data as JSON structures should use schemas where nodes either have values or descendants but not both.
Persistence
In YottaDB, persistence is a property of a variable, visible in the variable name. Prefixing a variable name with a caret (^) makes its data persist beyond the lifetime of a process. Persistent data is concurrently available to other processes – and data persistence and sharing are what define a database! Where the Population nodes above cease to exist when the process in which they reside terminates, the ^Population nodes below are persistent, shared, database nodes:
^Population("Belgium")=1367000
^Population("Thailand")=8414000
^Population("USA")=325737000
Shared, persistent nodes in a database are called global variable nodes. Nodes that are private to a process with the lifetime of the process are called local variable nodes. The difference in persistence means that a local variable node and a global variable are different even if they superficially have the same name, i.e., Population(“Canada”) and ^Population(“Canada”) are different nodes.
Note: it is a wholesome programming practice to use related names where the data is related, e.g., a process may copy the ^Population(“Canada”) node or sub-tree to Population(“Canada”) to cache it in memory or to manipulate it. Using similar names for unrelated data makes for unmaintainable software.
With YottaDB’s database journaling, databases are fully recoverable in the event of an unplanned system outage.
Transaction Processing
YottaDB implements transactions with strong Atomic, Consistent, Isolated, Durable (ACID) properties. Consider application logic to move $100 from a savings account to a checking account, which conceptually consists of the following steps:
- Validate that the accounts exist, that the requested transfer is permitted, that there is sufficient balance, that the transfer request is authenticated, etc.
- Subtract $100 from the savings account.
- Add $100 to the checking account.
- Compute and debit any applicable service charges.
- Create a record to log the transaction.
Consider that application logic executing concurrently with an update to business rules affecting minimum balances and service charges, and a balance inquiry. Each of the three is implemented as an ACID transaction.
Atomicity is the property that the entire transaction happens or none of it happens. For example, in the event of a system malfunction, it should not recover to an intermediate state such as between the withdrawal from savings and the deposit to checking.
Consistency is the property that the database should never be observable in a state that is inconsistent (the process of course sees its own data that it is manipulating in a transient state).
Isolation is the property that each transaction execute and commit as if it were the only transaction active on the system. For example, if the money transfer transaction commits before the transaction that updates business rules,
There is a duality between Consistency and Isolation – as a practical matter, it is not possible to provide strong Consistency without strong Isolation and vice versa. YottaDB provides strong Consistency and Isolation. Strict Serializability implies strong Consistency and Isolation, and vice versa.
Durability is the property that once a transaction is committed, the database state change it represents is permanent, even if the computer crashes. YottaDB implements Durability by logging each transaction to a journal file, and “hardening” that journal file to non-volatile storage as part of the logic that commits a transaction.
Business Continuity
While Durability is based on recovering application state from persistent non-volatile storage, business continuity of an application requires recovery of application state even in the face of loss of that non-volatile storage, e.g., the unplanned loss of a data center or a geography. Furthermore, in the event of unplanned loss of a data center or a geography, a mission critical application should continue to be available from another data center.
YottaDB achieves business continuity with real-time replication. Transactions are processed on a single instance for serialization performance (serialization is slower when it the decision making required for strict serialization is distributed over multiple instances). As journal records are written to journal files, those updates are streamed in real time to as many as 16 secondary instances. Each of those 16 secondary instances can stream the updates it receives in real time to 16 more instances (for up to 256 tertiary instances), and so on, without any limit imposed by YottaDB.
In the event of loss of the instance in that primary role, any of the instances to which it is replicating can be switched from a secondary (or tertiary, or other downstream role) to the primary role. When the instance in the original primary role is recovered, it operates in a secondary role, and catches up with transactions processed by the instance that took over the primary role.
Given the strict serialization requirements of demanding applications such as banking core processing, YottaDB provides mechanisms for an application to restore strict serialization after such an outage.
The operation of the primary instance that originates updates is unaffected by the state of any replication connection or secondary instance receiving updates. The instances share no hardware or software resources, and thus one instance is unaffected by any other instance.
Note: with n instances, it is possible to provide business continuity in the face of at most n-1 unplanned outages. Since the number of instances is always a finite number, absolute business continuity does not exist, and the number of instances is a business decision rather than a technical decision resulting from a YottaDB limit.
As YottaDB replication replicates only logical update information, network bandwidth use is parsimonious compared to techniques such as storage-mirroring. Furthermore, YottaDB can optionally use the standard zlib compression library to further reduce bandwidth used.