Update Oct 21, 2020:
See https://yottadb.com/product/octo-sql-for-analytics/ for a high level introduction to Octo.
Octo is a YottaDB plugin for using SQL to query data that is persisted in YottaDB’s key-value tuples (global variables).
Conforming to YottaDB’s standard for plugins, Octo is installed in the $ydb_dist/plugin sub-directory with no impact on YottaDB or existing applications. In addition to YottaDB itself, Octo requires the YottaDB POSIX plugin. The popularity of SQL has produced a vast ecosystem of tools for reporting, visualization, analysis, and more. Octo opens the door to using these tools with the databases of transactional applications that use YottaDB.
Background and Motivation
At the core of YottaDB is a hierarchical key-value data-store accessed and manipulated by native imperative programming APIs in M and C, which are in turn wrapped to create APIs in other languages such as Go, with more to come.
This approach is well-suited to so-called transactional systems – applications whose primary objective is to change the database state. Examples include:
- Core banking systems, the systems of record for bank balances
- Electronic health record systems
- Library systems, for tracking the locations of items, loans, due dates, etc.
- Election systems for registering voters and counting votes
The imperative programming model works well for transactional systems, because transactions involve state changes with associated rules, which are easily encoded as actions. In other words, imperative programming works well when the “how” to accomplish a desired outcome can be articulated clearly.
There is another class of systems for which the imperative model does not work well, where even though the “what” of a desired outcome can be articulated, the “how” is not clear.
Consider a candidate for the Rhinoceros Party who wants to spend a morning campaigning by knocking on doors in the Transylvania primary election. From the voter record dataset provided by the State, he wants to target members of the Rhinoceros Party in his precinct who have voted in at least three of the last ten primary elections. He wants the results grouped by street and then by even and odd numbered addresses so that he can walk up one side of a street and then down the other. To allow him to affably greet whoever answers the door at each address, he wants the names, genders, and ages of all voters at the selected addresses, regardless of whether they are members of the Rhinoceros Party.
While the “what” is clear, the “how” is not. Should he first screen for membership in the Rhinoceros Party? If Rhinoceros Party members are a minority of the electorate, this would be a good strategy, because it would whittle down the numbers considerably, but if they are in a majority, a better strategy would be to first screen those who voted in at least three of the last ten primary elections, as often only a minority of an electorate votes in primary elections.
Query languages allow one to specify the desired output, letting the computer figure out out how. There are many query languages (e.g., see one list) but the one most commonly used, because the data of many applications fits the relational model, is Structured Query Language or SQL.
How does Octo work?
Octo must be told what tables (relations) are defined, and how to access the data for each column of each table. While some data is likely just a value stored in the database (each voter’s name, address, gender, registered party affiliation, etc.), other data must be derived or computed such as, a voter’s age, whether a voter has voted in three or more of the last ten primary elections, and whether a door number is even or odd.
Octo’s Data Definition Language (DDL), based on SQL-92 and extended to allow the locations for data to be specified, maps tables and columns to global variable nodes, pieces of a global variable nodes, or computed values of functions.
Octo compiles the DDL into an internal binary form, and stores the compiled DDL in global variables. Global variables that Octo uses all begin with ^%ydbocto and Octo can optionally use its own global directory for its global variables. This global directory separation means that, with some caveats, Octo can operate with read-only access to an application database.
For example, Octo can be made to operate with a BC replication instance, on which the only updates permitted to the application database are those the local Receiver Server receives from an upstream Source Server.
When Octo receives an SQL query it converts the query into a canonical form. Its lexical analyzer for SQL queries is generated using flex, followed by a parser generated using Bison. Octo then converts the parsed query into a canonical form, generating M code for the query from code templates, if such M code does not already exist. Generated M routines have names derived from hashes of the canonical forms of the queries, e.g., %ydboctoP48C7NDA7tps6jVF1Ga7hS3 – names that will not clash with application routine names. As YottaDB compiles M routines to object code for execution, Octo SQL queries run as native machine code with direct access to the database.
Octo performs optimizations both in deriving the canonical form and in code generation. As performance optimization is a journey, not a destination, Octo has a set of optimizations today, and will have more tomorrow.
Client Access
Although Octo supports running queries and getting results on the server (by running the octo executable from the shell), a more common use pattern is for client applications running on their own systems to send queries to the server and to get results over a network, using a protocol such as JDBC or ODBC. Databases typically provide JDBC and ODBC software drivers that run on client systems to expose a standard API for client applications to call. These drivers run on “wire protocols” typically layered on TCP/IP.
Octo adopted the wire protocol of the popular free / open source relational database PostgreSQL. rocto, a listener for the PostgreSQL wire protocol, can be configured to listen at a TCP port. Leveraging the PostgreSQL wire protocol means that Octo does not need to develop its own set of ODBC/JDBC drivers, and clients can use existing PostgreSQL drivers.
In keeping with YottaDB’s free / open source ethos, we test and support Octo with SQuirreL SQL at this time, but will likely add others in the future.
Mapping
Although one reason for the popularity of NoSQL databases is the fact that they do not impose rigid schemas, any successful large application will have a schema – even if an informal schema, and even if not normalized. While generating a DDL for an existing application can be done manually, generating it automatically is likely to be more robust and maintainable for long-lived applications.
As an example of an automated mapping tool, YottaDB developed OctoVistA, a tool for automatically generating the DDL for any VistA implementation that uses VistA’s Fileman to manage the database rather than directly accessing global variables.
Representative Configuration
The diagram shows a representative configuration of Octo in a production deployment of VistA.
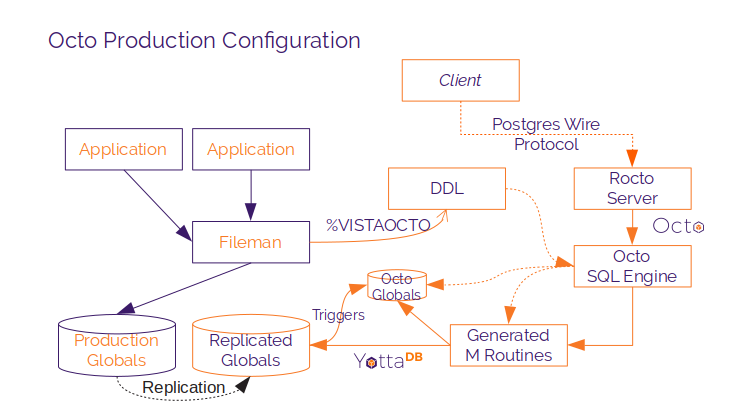
Imperative application logic uses Fileman to access and update production globals in a production instance, shown with orange letters inside purple figures. YottaDB SI replication is used to create an instance for decision support using Octo, shown with purple letters inside orange boxes. %VISTAOCTO generates a DDL from Fileman, on either the originating primary instance or replicating secondary (Octo) instance. On the Octo instance, the Octo SQL engine reads and compiles the DDL, storing the compiled DDL in global variables.
When the Octo SQL engine receives a query, either on the server or from a client, it compiles the query and converts it into the canonical form. Using the compiled DDL, it generates an M routine for the query if one does not exist. When the M routine runs, if any cross references are needed, it generates them and creates triggers to maintain the cross references as further updates are replicated to the database.
Status and Roadmap
At present (early July, 2019), following an Alpha test with an intrepid user, Beta test releases of Octo are available, and YottaDB is working with a core set of Beta testers. Based on their feedback and on additional automated testing we will follow up with a production release of Octo, which we anticipate in late 2019.
Octo currently supports read-only access from SQL, and is therefore useful in conjunction with imperatively programmed applications which update database state. As SQL supports all “CRUD” (Create, Read, Update, Delete) database operations, following the release of a production grade version of Octo for reporting (i.e., read-only access), we intend to work towards versions that support read-write access as well.
Although SQL-92 (also known as SQL2) is the standard that is most widely supported by relational database management systems, there are newer versions of the standard. Octo supports mostly SQL-92 with some extensions from newer standards, and our plan for the future is to enhance Octo with functionality from the newer standards.
As PostgreSQL is the leading free / open source relational database management system, its footsteps are good ones for Octo to follow. Given the plethora of relational database management systems, YottaDB intends to add compatibility with an increasing set of such systems over time.
Octo’s strength is the fact that it is built on YottaDB. Access to and control over YottaDB’s global variables gives Octo users the ability to fine-tune the storage for application needs. For example, a primary database could be have its global variables organized for scaling of a transaction processing database. Replicating to another instance using a schema change filter as supported by YottaDB replication could be used to create an instance with the same relational schema, but completely different global variables, optimized for decision support.
We appreciate your company as we embark on this journey of adventure in the land of databases.
YottaDB r1.26 ReleasedYottaDB r1.26 is a major release on our roadmap to world domination (we may never get to our destination, but we will have fun – and release great software – along the way!).
Multi-Threaded Applications
r1.24 extended the Simple API with field-test grade implementations of functions to support multi-threaded applications. In getting to r1.26, we have implemented the breadth and depth of automated testing we require for production grade functionality. In r1.26, not only are we able to consider the Simple API functions for multi-threaded applications as production grade and Supportable, we have also made their performance comparable to functions that support single-threaded applications.
Improving Ease of Use
Sourcing ydb_env_set addresses an expanded set of use cases, including setting up and automatically recovering a database (e.g., when coming up after a crash). This brings to applications in all languages functionality that was previously available to M applications through the ydb script in a more limited form. ydb_env_set also automatically sets environment variables to access YottaDB plugins that comply with the plugin architecture standard, such as Octo.
Preparing for Octo

At its core, YottaDB is a hierarchical key-value data-store which is accessed and manipulated by native imperative programming APIs in M and C that are in turn wrapped to create APIs in other languages such as Go. Octo is a YottaDB plugin to provide SQL access to YottaDB databases. As YottaDB is a 100% free / open source software company, you can track Octo as it is developed. Octo is currently in Alpha test, with a Beta test scheduled to start on Monday, July 8 in Bethesda, Maryland, with a training course in conjunction with the OSEHRA 2019 Summit.
YottaDB r1.26 has enhancements and fixes that Octo needs. Please look out for announcements about Octo in the near future.
And More…
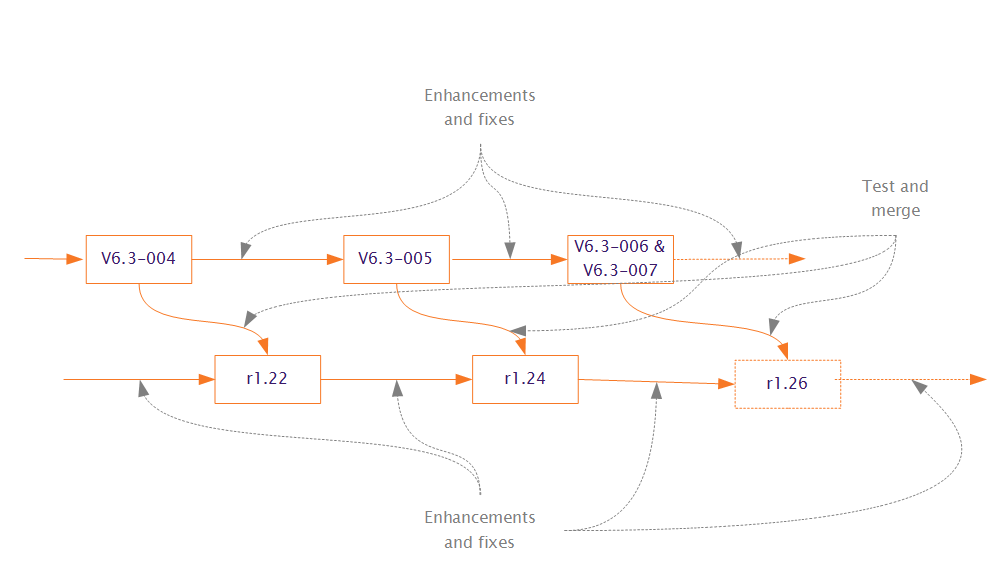
YottaDB is upward compatible with both YottaDB r1.24 as well as GT.M V6.3-006 and V6.3-007. The diagram shows the relationship between YottaDB and GT.M. YottaDB releases include fixes and enhancements made by the GT.M team to the code base, as well as fixes and enhancements made by the YottaDB team. This relationship allows us to promise YottaDB users our drop-in GT.M compatibility and satisfaction guarantee.
As with any YottaDB release, r1.26 includes a number of enhancements and fixes, as detailed in the release notes.
April फूलThey say April showers bring flowers, and here at YottaDB, we take the day seriously. Forsythias burst into bloom just this morning, and blooming eastern redbuds are fooling us into thinking that the dogwoods are flowering early this year.
We have some important announcements to make today.
As you know, performance is our passion, and every release of YottaDB is faster than its predecessors. We are pleased to announce that thanks to our new Tachyon™ technology YottaDB NonCausal operates faster than the speed of light and therefore gives answers before you run the program. The faster-than-light world is a strange place with counter-intuitive results. Since time moves backwards – software is announced before it is released, it is released before it is tested, it is tested before it is developed, and development comes last of all. So, all we can say about it is Watch This Space™!
YottaDB NonCausal also supports our brand-new ALKALI (A Lithium Kalium Alloy Levitates Isolation) transactions. In ALKALI transactions, the Isolation is so light that it completely neutralizes ACID transactions, resulting in pH neutral software that will never upset users or give them heartburn.
We thank you for your interest in YottaDB, and invite you to come back for more exciting software news, as we Go towards a production grade release, you can C that we have not been immunized against MUMPS, and will shortly be a welcoming place for Rustaceans!
Images used:
Purple and Yellow Petal Flower, Cindy Gustafson
Translation:
फूल
Imagine an Anchovy Pizza Company1 that is famous for its great pizzas. However, since every pie they make includes anchovies among the toppings, its customers are naturally limited to those who are enthusiastic fans of anchovies and those who, while they may not especially care for anchovies, have found a combination of toppings including anchovies that blend well together to give them pizza they enjoy.
As discussed in our blog post The Heritage and Legacy of M (MUMPS) – and the Future of YottaDB, MUMPS is both a procedural programming language and a NoSQL database. YottaDB’s upstream GT.M code base is like the Anchovy Pizza Company in that the MUMPS programming language and the MUMPS database are inseparably integrated – although it is possible to access the database from any language that can make C-compatible function calls, such access requires a small API to be created in MUMPS, as a software shim, which application code in the other language must call. The anchovy lovers who frequent the Anchovy Pizza Company2 are those already programming in MUMPS, and those have found a combination of toppings to love have applications programmed in a high level language that compiles into MUMPS for execution.
We make the same great pizzas as the Anchovy Pizza Company – indeed, more than half our number made pizzas there, and each member of our original team made anchovy pizzas for over twenty years. But there is an important difference: you can have any topping you want on our pies. If you love anchovies, we make the best anchovy pizzas, but if you don’t care for anchovies, or you are a vegetarian, we will make you a great pie with your choice of topping.
In r1.20, YottaDB created a native C API that is tightly bound to the database. In r1.24, we extended that API to support multi-threaded applications, and followed up with a Go API. In the not-too-distant future, we hope to add support for Rust as well as beyond that to popular languages such as Python. SQL? It’s coming. David Wicksell has released nodem which is node.js API. JSON? JDS-GTM has it. All these APIs are toppings for the great database pizzas we make.
Chocolate chip & dill pickle topping? Sure if our customers want it, we’ll bake it!

[1]. For readers outside the United States who may not be familiar with the idea, anchovies as a pizza topping have enthusiastic fans as well as those who vehemently dislike it. Anchovies on pizza generate passion, with a small minority in the middle.↩
[2]. As well as similar pizza companies that also include anchovies, but are not as forthright about it.↩
Images used:
[1] By Etrusko25 – Own work Foto di Alessandro Duci, Photo taken in Liguria, Italy
[2] Amazing Pizza, David Adam Kess
[3] Photo by Fancycrave.com from Pexels
Towards our goal of “YottaDB Everywhere”, we have invested heavily in exposing YottaDB’s core data management. In r1.20, we released a highly performant C Simple API with minimal software between the API and the data management engine. In r1.24, we extended that API to support multi-threaded applications. As the lingua franca of computing, accessible from all programming languages, a C API allows us to create “wrappers” to provide application developers in popular languages with native APIs, each of which aims to fit well with the culture and paradigms of its language.
The first language for which we have created a wrapper is the popular Go language.
As recounted by Go co-designer and developer Rob Pike:
… Go’s design considerations include rigorous dependency management, the adaptability of software architecture as systems grow, and robustness across the boundaries between components. … Go is a compiled, concurrent, garbage-collected, statically typed language developed at Google. It is an open source project: Google imports the public repository rather than the other way around. .… Go is efficient, scalable, and productive.
While those are good reasons to create a Go wrapper for YottaDB, the language has features that threw down a gauntlet of technical challenges that we had to overcome.
Instead of YottaDB’s traditional model of concurrency based on processes, global variables, locks and optimistic-concurrency control, Go’s abstractions are at a higher level, implementing the abstractions of Communicating Sequential Processes using independently executing coroutines (called Goroutines) dynamically scheduled over a set of operating system threads within a process. This means that the YottaDB runtime system cannot use a thread-id to identify requests, and must instead use a context, called a “tptoken”, as described in our blog post YottaDB Support for Multi-threaded Applications.
Go blends the features of procedural, as well as object oriented, languages. While Go has functions, like those of procedural languages, a Go structure can have associated methods. A method is conceptually like a function whose first parameter is a pointer to a structure. In designing the API, we had to make decisions as to whether to package each unit of functionality as a function or a method. For the purpose of this blog post, “function” is used generically to mean either a function or a method, whereas “method” specifically refers to methods operating on structures.
As one of the design goals of Go is safety, pointers to Go’s heap space and to functions or methods are not permitted to be passed to non-Go code such as the YottaDB runtime, Since data from YottaDB is often passed back to YottaDB – for example, getting the next subscript at a level in the tree and accessing that subtree, or getting data from a cross-reference node and using it as a subscript – we felt that minimizing copying by cgo of data between Go and YottaDB heaps was important for efficiency and performance. This led to a design decision to leave the data in YottaDB, and to pass pointers to that data between Go and YottaDB, allowing Go application code to manipulate pointers rather than data, using the pointers to access or provide data when needed. However, while such a design may be computationally efficient, it has (at least) two consequences:
- Memory management is conceptually harder than allowing strings to be copied back and forth on each call.
- YottaDB cannot know when a structure allocated in its heap is out of scope for Go application code, and should be freed or garbage collected, in order to prevent memory leaks.
Our solution to the first was to create two families of functions, an “Easy API” and a “Simple API”. The Easy API is a set of functions (not methods) that copy strings between Go and YottaDB on each call. The solution to the latter was to use finalizers to free YottaDB structures when the Go structures pointing to them go out of scope.
Our goal with wrappers for YottaDB is for each wrapper to fit in as much as possible with the ecosystem and culture of its language. This means that on a system or container with YottaDB installed, installing and using the Go wrapper is as simple as:
- Install with:
go get lang.yottadb.com/go/yottadb
- To use, include
import “lang.yottadb.com/go/yottadb”
in application code
- Documentation is at https://godoc.org/lang.yottadb.com/go/yottadb (with complete documentation in the Multi-Language Programmers Guide)
We are also providing a Dockerfile including the packaged Go wrapper.
Please use the YottaDB Go wrapper, and tell us what you think!
References:
- IEEE Spectrum’s Interactive: The Top Programming Languages 2018
- The RedMonk Programming Language Rankings: June 2018
- TIOBE Programming Community Index
Images Used:
Go Gopher, Renee French.
The design is licensed under the Creative Commons 3.0 Attributions license.
Read this article for more details: https://blog.golang.org/gopher
r1.24 is a major release on our path to “YottaDB Everywhere” through better integration with package management and Simple API extensions to support multi-threaded applications or those using coroutines, 64-bit Linux on ARM, and much more, including a large set of functional & performance enhancements as well as fixes to issues detailed in the release notes.
Better integration with package management:
pkg-config is a standard tool on Linux systems for managing package versions, for example, to query the location and latest installed version of a package. YottaDB is now part of this ecosystem: the ydbinstall script creates a pkg-config file for YottaDB at /usr/share/pkgconfig/yottadb.pc. In turn, this means that an application can write a script to use YottaDB without the script needing to be updated when a new YottaDB release is installed on a system, or if a YottaDB release is installed in different directories on different systems, e.g.
source $(pkg-config --variable=prefix yottadb)/ydb_env_set # setup environment gcc -I $ydb_dist -L $ydb_dist -o myprog myprog.c -lyottadb ./myprog
or
source $(pkg-config --variable=prefix yottadb)/ydb_env_set # setup environment mumps -run myprog
Fitting into the standard ecosystem becomes increasingly important as we release YottaDB wrappers providing standard APIs for a variety of languages starting with Go (see below).
Simple API extensions for multi-threaded applications:
Although the YottaDB engine is single-threaded, applications can be multi-threaded, and often are. Furthermore, in the case of Go, a process can have hundreds to thousands of coroutines (called Goroutines) which are dynamically scheduled over a smaller number of threads within a process, i.e., during its lifetime, a coroutine may well execute on different threads at different times. In r1.24, YottaDB’s Simple API is extended with functions to support multi-threaded applications. We recently blogged about this. Look for an announcement in the very near future telling you about the YottaDB Go wrapper. A wrapper is a small software shim that accesses YottaDB through its Simple API to provide a YottaDB API in another language, an API that fits in with the paradigms of that language and is intuitive to application developers working in that language. Note that the Simple API extensions for multi-threaded applications is field test grade functionality, i.e., suitable for development and testing but not for production. In the near future, and no later than the next YottaDB release, we anticipate that these API extensions will become production grade. Except for the functions to support multi-threaded applications, the rest of YottaDB r1.24 is production grade, i.e., suitable for production use.
The new 64-bit ARM platform:
With the advent of 64-bit ARMv8 CPUs, and Linux distributions that make use of that extended capability, 64-bit Linux on ARM is a computing platform worth taking seriously. With r1.24, YottaDB adds 64-bit Linux on ARM as a fully Supported platform. Thanks to community member Steve Johnson for contributing the port.
A large set of enhancements and fixes:
Although too numerous to list here (full details in the release notes), YottaDB comes with numerous functional and performance enhancements, as well as fixes. Some are implemented by YottaDB, where as others are inherited from GT.M V6.3-005, whose code base is merged into YottaDB r1.24. r1.24 also includes fixes to issues in the GT.M code base. For example:
- Application code executing on a release of YottaDB can access database files on the same machine in use by another version of YottaDB/GT.M.
- Several Improvements to the ydbinstall script.
- Journal records fed to replication filters include timestamps.
- YottaDB changes terminal characteristics only during a READ or in direct mode.
- Support for TLS 1.3 in the reference implementation of the encryption plugin.
- A symbolic constant YDB_RELEASE in libyottadb.h to allow C applications to determine the YottaDB release at compile time.
YottaDB is upward compatible with YottaDB r1.22 as well as GT.M V6.3-005.
Please do try YottaDB r1.24, and tell us what you think of it.
Solving the 3n+1 Problem with YottaDBOur goal of “YottaDB Everywhere” aims to provide rock solid, lightning fast, secure persistence wherever it is needed. This means providing standard, supported, YottaDB APIs (called “wrappers“) to access YottaDB from popular languages. This in turn leads to several needs:
- While there are certainly superprogrammers who write code using new APIs after reading the user documentation, lesser mortals, among whom this author counts himself, are more comfortable finding working code, of which bits can be copied and suitably adapted. In order to allow such a programmer to focus on the code and not get distracted by the problem being solved, it is desirable to find a simple problem with a compact solution which nevertheless uses a range of functionality provided by an API.
- Choosing the right language, implementation, and API can make it easier (or harder) to achieve the objective in situations when performance matters. Comparing programs that solve the same problem using the same algorithm make it easier to make apples-to-apples comparisons of different languages and implementations.
- Meaningful application benchmarks involve specific workloads of specific applications, workloads that are representative of situations in which application performance / throughput matter. As such benchmarks are costly to run, there is a need for simple benchmarks that are easier to run, and which can narrow down the range of full application benchmarks that must be run. A good simple benchmark is one that, based on simple inputs, can run on machines ranging from a low end system like a Raspberry Pi Zero to a high end server, execute from seconds to hours, and run on databases ranging from Megabytes to Terabytes.
- Importantly, in a software company, where many of us are proud to be geeks, we want to have fun!
Our solution to this is to create programs to solve the “3n+1” problem.
The functional goal of the 3n+1 problem is as follows:
Given an input integer i, report the length of the longest 3n+1 sequence of an integer from 2 through i, as well as the largest number encountered in any sequence. Note that multiple integers in the range may have 3n+1 sequences of that length, and multiple 3n+1 sequences may include that largest number. Also, the longest 3n+1 sequence and the largest number may or may not start with the same integer.

By providing solutions to the same problem in multiple languages, our goal is to provide working sample code as a template for developing applications, as a learning tool and as a mechanism to compare the relative performance of various implementations.
Starting with any positive integer n, a sequence of numbers (the 3n+1 sequence) can be generated as follows:
- if n is even, the next number is n/2
- if n is odd, the next number is 3*n+1
Lothar Collatz conjectured that for any finite n, there is a finite length 3n+1 sequence that ends in 1.
For example, the 3n+1 sequence for 3 has a length of 7 steps (3, 10, 5, 16, 8, 4, 2, 1) and the largest number in the sequence is 16.
Our practical goal is to illustrate the use of YottaDB’s key value store to solve this problem.
As the core functions of a database are sharing and persistence:
- There are multiple collaborating workers (processes, threads, or co-routines). By storing results in a database, collaboration allows workers to build on one anothers’ work. For example, if a worker computing the 3n+1 sequence starting with 3, finds that the length for 8 is already in the database, it can stop, and enter the results for 16, 5, 10, and 3 in the database, working backwards along the sequence to its initial number.
- The range of input numbers is organized into blocks of concurrent numbers: for example, an input range of 1,000,000 numbers can be organized into 500 blocks, each of 2,000 concurrent numbers. Until all 3n+1 sequences are computed, each worker loops to pick up the next available block and compute the 3n+1 sequences for that block.
- In the event of a crash, recovering the database and re-running the same input re-uses the results from the prior run. YottaDB ensures that the recovered database has the Consistency required for correct results from the second run (or third, fourth, or subsequent run, in the event there are multiple crashes). YottaDB’s ACID transactions are used to make the application self-checkpointing.
Until it reaches the end of the input, the program reads lines, each of which has:
- A required parameter, i, the upper end of the range for which 3n+1 sequences are to be computed.
- Two optional parameters, the number of workers (defaulting to twice the number of CPUs) and the size the blocks of concurrent numbers (defaulting to approximately the input range divided by the number of workers).
For each input line, the program produces a line of output:
- The input i.
- The number of workers.
- The block size (if the input block size is greater than the default, the program uses the default).
- The length of the longest 3n+1 sequence found.
- The largest number encountered in any 3n+1 sequence.
- The elapsed time in seconds, with a resolution of milliseconds.
- The total number of database updates.
- The total number of database reads.
- Database updates per second (total updates divided by elapsed time).
- Database reads per second (total reads divided by elapsed time).
To illustrate the use of YottaDB in-process data management (it is more than a database), even when a language implementation has packages and data structures such as hash tables, programs use YottaDB local variables.
A manager organizes the work, launches workers, and reports results when all workers are done. In order to minimize artifacts from launching workers (an activity in which YottaDB plays no part), each worker waits till the manager indicates that all workers are launched, before starting its work. The manager then waits for all workers to complete before it can report results. Where the manager and workers are processes, this coordination is accomplished with YottaDB’s hierarchical locks. Since YottaDB locks are resources owned by the process, in implementations where the manager and workers are threads or co-routines, coordination is achieved using non-YottaDB mechanisms.

Although quick and easy, the 3n+1 technique has limitations, especially when it comes to using it for benchmarking and performance tuning:
- It is update intensive: about 40% of its database accesses are updates. Perhaps 10-20% of database accesses in an update-intensive workload from the “real world” are likely to be updates.
- It is database access intensive: it performs minimal computation for each database access. A real application would most likely perform one or more orders of magnitude more computation for each database access.
- Database accesses are small: except for cross-references, the data transferred in each database read or update would be much larger in a real world application.
Of course, most importantly, what you care about is not the performance of 3n+1 programs: you care about your application, with a critical workload for that application. Nevertheless, the 3n+1 programs are an important tool for learning and benchmarking toolboxes.
In the future, we anticipate blogging about actual results from our 3n+1 programs which we will make available so that you can run them. Meanwhile, please do send us your comments.
Images Used:
[1] A graph, generated in bottom-up fashion, of the orbits of all numbers under the Collatz map with an orbit length of 20 or less
[2] A graph with the value of the number of steps to reach 1 applying Collatz procedure to numbers between 2 and 200.
[3] Collatz Conjecture, XKCD
[4] The Collatz map can be viewed as the restriction to the integers of the smooth real and complex map. Iterating the optimized map in the complex plane produces the Collatz fractal.
Background
The YottaDB database engine operates within the address space of the application process, and is itself single threaded. Why? There is a historical reason as well as a current reason.
When the YottaDB code base was first developed in the 1980s, operating systems did not support multiple threads within a process. Furthermore, for many years, the database was tightly coupled to the M language, which supports multiple concurrent processes, but not multi-threaded processes. Today, even as it continues to support M, YottaDB has grown beyond M: YottaDB provides a tight integration with C, which does support threads, and through C to languages.

Since the YottaDB code base has been continuously invested in, why is it still single-threaded more than thirty years after it first saw daily production use in a mission-critical application? The reason is that there is not an obviously significant benefit from making the engine itself multi-threaded. Whether updates are generated by multiple processes or multiple threads, database accesses must still be internally consistent, database updates must still be serialized, and transactions must ensure ACID properties. YottaDB gets its extraordinary performance in part because processes use shared memory to cooperate in managing the database. It is not just the logic of the database engine that is in the address space of the process – the shared memory control structures and data are also in the address space of the process. With the threads in a process already sharing an address space, we have not been able to quantify a benefit from making the engine itself multi-threaded. While there is very likely at least some performance benefit to making the engine multi-threaded, we have not at this time identified a performance benefit significant enough to warrant the investment.
While there may not be value in making the database engine multi-threaded, there is definitely value in allowing multi-threaded applications to benefit from integration with YottaDB – applications are multi-threaded, and can benefit from YottaDB’s data management capabilities. What is needed is an API that multi-threaded applications can use to access YottaDB. This post discusses the need for differences in the API used by single-threaded applications vs. multi-threaded applications, and how YottaDB’s single-threaded engine supports multi-threaded applications.1
Single- vs. Multi-Threaded Applications
Function calls are synchronous. When a single-threaded application calls a YottaDB function such as ydb_get_s(), the YottaDB engine shares a call-stack with the application code and executes in the same thread. Except for recursive calls that implement transaction processing (see below), the application is blocked until YottaDB returns to the caller.

In a multi-threaded application, the YottaDB engine cannot execute in the same thread as the caller, because after servicing a request from one thread, application logic in a different thread may require service. Therefore, the YottaDB engine must execute in its own thread, different from that of any application thread. Instead of calling ydb_get_s(), for example, the application thread calls the function ydb_get_st() which executes in the same thread as the caller. ydb_get_st() puts a message in a process-private queue for the thread executing the YottaDB engine, then waits for and returns the response from YottaDB to the caller. While the call to ydb_get_st() is synchronous for the caller, which is blocked till ydb_get_st() returns, other threads continue execution. The YottaDB engine services queued requests. With the exception of a tptoken parameter that the multi-threaded functions require (see Transaction Processing below), the APIs track each other with a few differences:
- As YottaDB can execute either in the same thread as application code that calls it, or in a different thread, but not both, an application can either use the single threaded API or the multi-threaded API, but not both. The first call to the YottaDB engine initializes the engine appropriately, and subsequent calls must match that initialization (or get an error).
- As the M language is single-threaded, any execution of M, either from the shell, or a call-in from C to M initializes the engine for operation in a single-thread.
- Some utility functions simply execute in the thread as the application code that calls them, whether in single- or multi-threaded applications, and do not need separate single- and multi-threaded versions.
Transaction Processing
YottaDB uses Optimistic Concurrency Control to implement high throughput transaction processing with fully ACID transactions. Single threaded applications call ydb_tp_s() and provide it with a function f_t() to execute the logic for the transaction. ydb_tp_s() calls f_t(), which in turn can call YottaDB directly, or call other functions that call YottaDB.
Transaction logic that executes across multiple threads in a single process introduces complications not found in transaction logic that executes in a single thread. For example:
- A process has two application threads, T1 and T2, with YottaDB executing in thread T3. T1 calls ydb_tp_st() to perform a transaction whose logic is in function ft(). ydb_tp_st() queues a request for YottaDB and awaits a response; the caller is blocked till ydb_tp_st() returns.
- YottaDB spawns a thread T4 executing function ft(). Now both T2 and T4 are actively executing application logic.
- YottaDB receives a message on its queue. YottaDB needs a way to determine whether the request is from the logic in T2 which should block until the ydb_tp_st() called by T1 returns, or from T4, which YottaDB should process.
In order to determine whether a request on its queue is from T2 or T4 – and in the general case, to determine whether a request on the queue should be serviced – function calls that support threaded applications include a tptoken parameter as follows:
- When application code that is not inside a transaction calls YottaDB, it passes a tptoken value specified by the symbolic constant YDB_NOTTP.
- When ydb_tp_s() calls ft(), it generates and passes to ft() a tptoken value.
- ft(), as well as any calls to YottaDB made by any threads and functions that are part of the transaction logic of ft() should use the value provided by YottaDB to ft() when calling YottaDB.
In the example above, threads T1 and T2 would use YDB_NOTTP as the tptoken value. When YottaDB spawns thread T4 executing ft(), it generates a tptoken and passes it to ft(). When the transaction logic in T4 calls YottaDB, it passes in this tptoken. Thus, when YottaDB gets a message in step 3 of the example above, it determines the action to take based on tptoken:
- If it is the value it passed to ft() (the current token), it should act on the request.
- If it is YDB_NOTTP, YottaDB should defer acting on the request until ft() completes and YottaDB receives the return code.
- If it is any other value, YottaDB should respond to the message with an error.
More generally, YottaDB maintains a stack of tptoken values it has issued and which have not been closed (as a consequence of the functions implementing transaction processing logic completing their work). When receiving a request, if its tptoken is
- that of the current transaction level, i.e., on top of the stack, act on the request;
- that of a transaction level within the stack, defer acting on it till that token comes to the top of the stack; and
- any other value, it is an error.
In other words, tptoken is a transaction context. Except for calls to YottaDB that are outside any transaction context, and so identified by YDB_NOTTP, calls to ydb_tp_st() create transaction contexts that YottaDB provides to functions implementing transaction logic, and which they in turn must provide when calling YottaDB. The datatype of tptoken is opaque to application software (at least, as opaque as anything can be in the world of free / open source software), and if application code attempts any operation on a tptoken other than passing it back to YottaDB as a parameter, the consequences are unpredictable and likely to be hard to debug.
Since a tptoken is a context unassociated with a thread, it also works when a language like Go interfaces with YottaDB, which accesses YottaDB through the Simple API for threaded applications. A potentially large number (hundreds to thousands) of Goroutines are dynamically scheduled over a smaller number of process threads, and in the course of its lifetime, a Goroutine may migrate to execute on many threads. But the transaction context established by a tptoken stays with a Goroutine regardess of the thread on which it is executing.
Availability
Effective r1.242, YottaDB supports Simple API functions for threaded applications as field test grade functionality in a production release, with the intention of supporting them as production grade functionality in the next release. Access from Go is available as a wrapper that accesses YottaDB r1.24 & up via the Simple API for threaded applications, and in turn exposes a Go API that Go application code can use. It is our intention in the future to add wrappers for other languages, also accessing YottaDB via the Simple API for threaded applications.
Documentation is in the Multi-Language Programmers Guide. Please do use the Simple API for threaded applications from C, Go, or another language, and please do tell us what you think.
[1]. Except for transaction processing functionality, a single-threaded application can call the multi-threaded functions, but not vice versa.↩
[2]. Software and documentation expected to be released late 2018 / early 2019; see the code under development at https://gitlab.com/YottaDB/DB/YDB .↩
Featured Image : Woven Silk. Jim Thompson House, Bangkok, Thailand by Ranjani Hathaway
Other Images:
[1] A weaver works over a traditional ‘pit loom’, the ancient method of weaving cloth, in which the weaver sits with his legs in a pit with the looms spread out before him on the floor. He uses two pedals near his feet to separate the looms to create different patterns. Location: Near Pokhran, Rajasthan by Ranjitmonga
[2] A threaded needle by Jorge Barrios
In an effort led by OSEHRA (Open Source Electronic Health Record Alliance), YottaDB has joined international participants from South Korea (Pusan University; SooSangST Co., Inc. and Kyungpook National University), China (Harbin Institute of Technology) and the Kingdom of Jordan (Electronic Health Solutions) along with DSS, Inc. to create an internationalized version of the VistA Electronic Health Record (EHR) system.
The result of this project will be a VistA version capable of storing and displaying information in any language using Unicode.
Read more about the initiative here.
To GitLab from GitHubAs a free/open source software (FOSS) project, YottaDB doesn’t just provide source code tarballs with each release – we make public the commit history of our source code. We have just moved our repositories to GitLab from GitHub.
If you currently access our software on GitHub, you can continue do so in future. However, please create Issues against our projects on GitLab, and if you have forked our code, please send us merge requests on GitLab rather than pull requests on GitHub. Note that we have also changed the names of the projects on GitHub. While the former names continue to work to access the new repositories, we suggest updating your scripts at your convenience to access repositories using the new names.
While a change to GitHub ownership was the catalyst, the move to GitLab was already contemplated, as GitLab provides us with more functionality than GitHub, especially subgroups.
Subgroups
GitLab subgroups allow us to better organize our projects than the flat organization of GitHub, especially for when we grow to 5× or 10× the number of projects we have today (we may be small, but we dream big!). Thus, on GitLab, we currently have the following subgroups, each containing one or more projects.
- DB – for the core NoSQL database engine.
- YDB – the actual YottaDB database engine with native C and M APIs, the core technology at the heart of all our work.
- YDBDoc – user documentation; the source code for the documentation we publish on our documentation site.
- YDBTest – the automated test system for the YottaDB database engine.
- Demo – demonstrations of YottaDB.
- YDBMindWave – acquire and display EEG data using the Neurosky MindWave Mobile.1
- Lang – Language specific wrappers that make YottaDB natively available to application code. Each language wrapper has its own project. YottaDB wrappers allow applications written in multiple languages to natively share the same local and global variables.
- Octo – While YottaDB (YDB) is the NoSQL database engine that provides rock solid, lightning fast, and secure persistence at the core of all our software, it is primarily a data store with an API. The Octo subgroup provides schema-based database management and access.
- YDBDBMS – A project for SQL/JDBC and other database management capabilities. This project is currently under development.
- YDBPIP – A copy of the robust and proven PIP transaction processing application development and deployment platform released by the original developer and then abandoned in an expert-friendly state. YDBPIP provides both inspiration and source code for YDBDBMS.
- UI – graphical user interfaces and tools for building graphical user interfaces for YottaDB.
- YDBGDEGUI – a browser-based graphical user interface for GDE, the YottaDB Global Directory Editor used for mapping a logical database over a set of database files. This project is currently under development.
- Util – Programs that are generally useful.
- YDBgvstat – an application to capture and log database operational statistics, for monitoring, performance tuning, troubleshooting, and much more. It provides data in comma-separated (CSV) files to facilitate analysis in spreadsheets.
Notice that we have renamed all our projects using a scheme that starts with “YDB”. Anyone who forks our projects, along with other projects, will be able to easily distinguish YottaDB projects from others. If you see or hear us refer to a project as, say, gvstat, the actual project name is YDBgvstat.
Other
Apart from subgroups, GitLab provides other benefits as well, including:
- The ability to run GitLab on our own servers. While we don’t envision a need for it in the foreseeable future, we may wish to do so for operational, performance, and backup purposes. As a free / open source software (FOSS) project, using FOSS tools and infrastructure is more compatible with our ethos than proprietary tools.
- Finer grain control of users and roles. While we may not take advantage of this today, we will need it as we grow. Potentially simpler continuous integration / continuous delivery (CI/CD) – although the core YottaDB engine has its own extensive test system and framework that takes multiple servers and runs in several hours of elapsed time, smaller projects lend themselves to CI/CD. GitLab’s built-in CI/CD is potentially simpler to set up and use.
Conclusion
While a change such as this is potentially disruptive, we would prefer to make the change at this time when the number of projects is fewer than it will be in the future. We have done our best to make the change as much of a non-event as possible for you, our users. Please do let us know how it works for you.
[1] The YDBMindWave demo uses the original Neurosky MindWave Mobile. It has since then been replaced by the MindWave Mobile 2. We have not tested the demo on the latter. ↩